



文/腾讯科技 郭晓静
刚刚在上周开过发布会的零一万物创始人李开复,时隔不到一周再一次在线上亲自和小部分媒体沟通,并在沟通会的开始就表示“难掩兴奋,所以希望马上开发布会和大家分享这个消息。”
这个让李开复无比兴奋的消息就是,零一万物提交的“Yi-Large” 千亿参数闭源大模型在LMSYS Org发布的Chatbot Arena取得了总榜排名第七的成绩。
过去一年的模型能力大战中,每次新模型的发布,模型能力Benchmark评分就会作为标准动作被同时公布,来评测模型的各种综合能力。但是,究竟如何解读这些评分?哪些才是有公信力的评测标准集,行业内并没有统一的标准。
但是在Gpt-4o发布后,OpenAI CEO Sam Altman亲自转帖引用 LMSYS arena 盲测擂台的测试结果。
为什么Sam Altman会引用LMSYS 的结果?为什么在这个榜单取得成绩会让李开复兴奋不已?
LMSYS Org发布的Chatbot Arena,关键词是盲测和开放。用通俗的语言来描述就是,它的模式是通过众包的方式对大模型进行匿名评测,用户可以在官网输入问题,然后由一个或者多个用户并不知道品牌的大模型同时返回结果,用户根据自己的期望对效果进行投票。
在收集真实用户投票数据之后,LMSYS Chatbot Arena还使用Elo评分系统来量化模型的表现,进一步优化评分机制,力求公平反应参与者的实力。最后用Elo评分系统来得出综合得分。通俗地来讲,在Elo评分系统中,每个参与者都会获得基准评分。每场比赛结束后,参与者的评分会基于比赛结果进行调整。系统会根据参与者评分来计算其赢得比赛的概率,一旦低分选手击败高分选手,那么低分选手就会获得较多的分数,反之则较少。
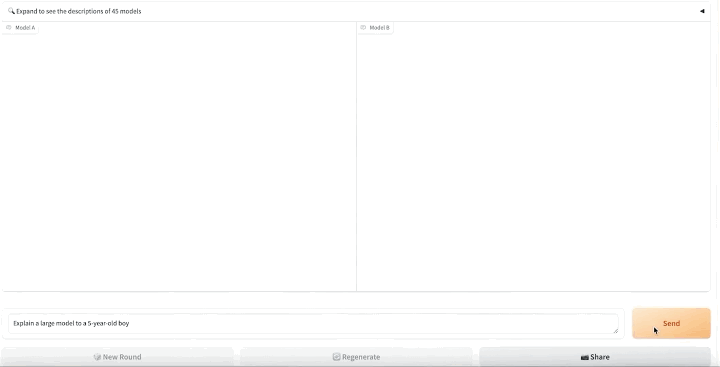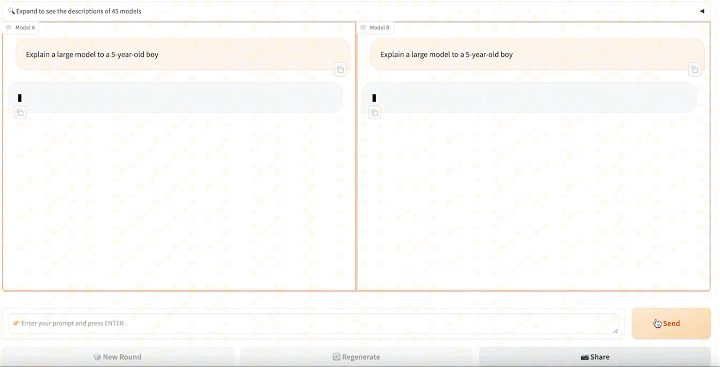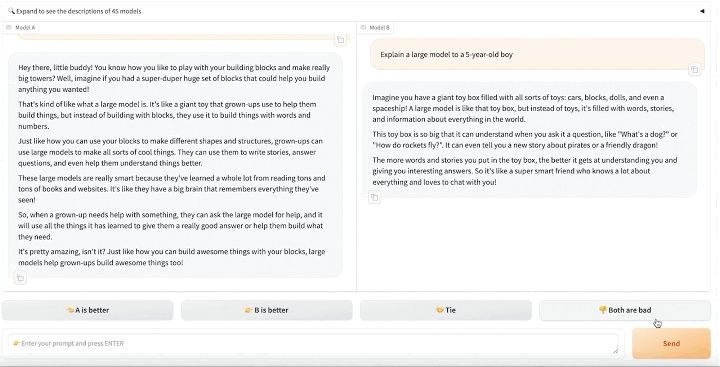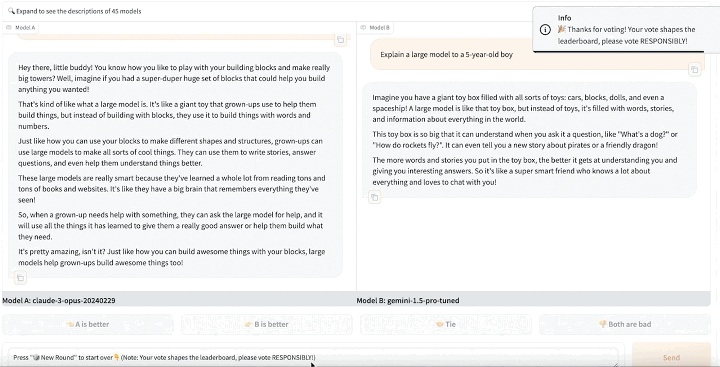
评测界面
在海外大厂高管中,不只Sam Altman,Google DeepMind首席科学家Jeff Dean也曾引用LMSYS Chatbot Arena的排名数据,来佐证Bard产品的性能。OpenAI、Google等自身的旗舰模型发布后第一时间提交给LMSYS,本身确实显示了海外头部大厂对于Chatbot Arena的极大尊重。
美国时间2024年5月20日刚刷新的 LMSYS Chatboat Arena 盲测结果,来自至今积累超过 1170万的全球用户真实投票数:此次Chatbot Arena共有44款模型参赛,既包含了顶尖开源模型Llama3-70B,也包含了各家大厂的闭源模型。
在这个榜单上,我们也看到了中国大模型的身影,智谱GLM4、阿里Qwen Max、Qwen 1.5、零一万物Yi-Large、Yi-34B-chat 此次都有参与盲测,零一万物提交的“Yi-Large” 千亿参数闭源大模型总榜排名第七,在总榜之外,LMSYS 的语言类别上新增了英语、中文、法文三种语言评测,开始注重全球大模型的多样性。Yi-Large的中文语言分榜上拔得头筹,与 OpenAI 官宣才一周的地表最强 GPT4o 并列第一,Qwen-Max 和 GLM-4 在中文榜上也都表现不凡。
“中国大模型与OpenAI旗舰模型的差距已经从7-10年缩短到了6个月。”李开复在线上沟通会上兴奋地表达。同时,他还呼吁?“无论是出于自身模型能力迭代的考虑,还是立足于长期口碑的视角,大模型厂商应当积极参与到像Chatbot Arena这样的权威评测平台中,通过实际的用户反馈和专业的评测机制来证明其产品的竞争力。这不仅有助于提升厂商自身的品牌形象和市场地位,也有助于推动整个行业的健康发展,促进技术创新和产品优化。”
同时,李开复也十分直接地抨击了“作秀式的评测方式”,他指出“相反,那些选择作秀式的评测方式,忽视真实应用效果的厂商,模型能力与市场需求之间的鸿沟会越发明显,最终将难以在激烈的市场竞争中立足。”
在简短的媒体沟通会上,李开复也坦诚回答了媒体关于模型评测的客观性、模型成本下降、全球大模型竞争差距等问题,以下为部分访谈内容实录:
Q:Yi-Large确实在中国大模型排名第一,但是确实前面还有国外大厂模型,您认为造成这个差距的原因主要是什么,是人才吗?如何追赶?
李开复:谢谢,我觉得首先我们也不能确定自己是中国第一,因为中国只有三个模型参加,我们也希望以后可以更确定的验证这一点。
但我也不是特别认为我们跟全球有差距,当然你要用他们最好的对我们最好的是有一定的差距,但是同时可能要考虑到他们比如说Google团队是2000人,OpenAI是1000人,在我们这里把模型加infrastructure加起来也不到100人,而且我们用GPU算力做这个训练不到他们的1/10,我们的模型尺寸也不到他的1/10。
换一个角度来说,如果只评估千亿模型,至少在这个排行榜上是世界第一,这些点我们还是很自豪,在一年前我们落后OpenAI跟Google 开始做大模型研发的时间点有7到10年,现在我们跟着他们差距在6个月左右,这个大大的降低。
这6个月怎么来?可以回到LMSYS 6个月以前的榜,或者今天比我们排名在前面的几家,几乎都是今年发出来的模型,去年的模型还在榜单上,我们已经打败了。
另外一个角度看,今天我们发布的这个模型在5月的时候可以打败去年11月之前的任何模型,所以我觉得也可以科学的推理出我们落后6个月。
6个月的差别我觉得不是很大,我觉得是一个不可思议的超级速度的赶追,这些方面我还是非常自豪。
如果你说美国人才有没有独特的地方?肯定是有的,从我写的《AI・未来 》这本书之后,我一直都坚持美国是做突破性科研,创造力特别强的一批科学家,在这方面在全世界是没有对手的。
但是在同一本书里我也说了,中国人的聪明、勤奋、努力是不容忽视的,我们把这7-10年降低到只有6个月,就验证了做好一个模型绝对不只是看你多能写论文,多能发明新的东西,先做或后做,做
 相关论坛
相关论坛
 相关广告
相关广告

 拨打电话
拨打电话